



Passkeys are all the rage these days, for obvious reasons. The idea of replacing a complex (or worse, reused) password you must remember with a unique generated secret stored on your machine for each resource you access is a dream come true.
At Wildfire, we're constantly looking for the next step up in security while maintaining balance as I described in my previous post, Three Pillars of DevSecOps. So is there an analogous concept to passkeys within cloud infrastructure? How can we leverage this to not only make the system more secure, but also make it more auditable and simpler for our developers to get the access they need, when they need it?
In this post, we will describe how we leveraged several technologies within Google Cloud to eliminate password authentication from our CloudSQL instances across the Wildfire infrastructure. In particular, we will cover: Google IAM, Workload Identity, RBAC, Service Account Impersonation and Terraform to show how we put it all together. Here's a small diagram of the new layout:
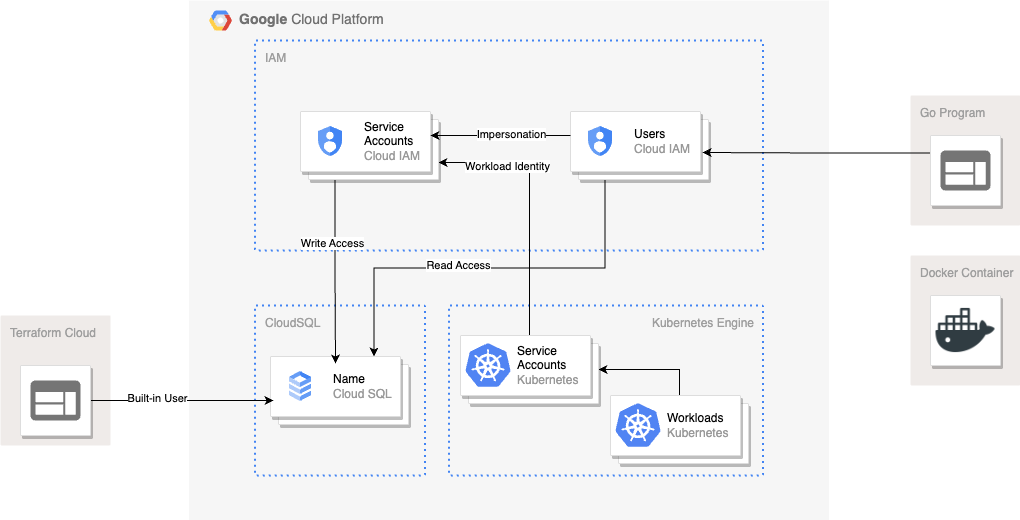
Google IAM
At Wildfire, we use Google's managed Postgres databases within CloudSQL instances. Traditionally, one connects to Postgres via a username and password. Perhaps a well-run team might have several users and passwords, allowing some amount of access control and auditability. But there is a better way: Google's managed databases support authentication via IAM (Identity & Access Management), meaning a user can authenticate directly to the database via their Google credentials.
This eliminates the possibility of credential sharing and the requirement of credential rotation when a team member leaves. It also provides the building blocks for fine-grained access control within the database, as low as row-level restrictions.
Workload Identity
Building on IAM, cloud providers often provide support for something called Workload Identity. Using Workload Identity, an identity of one type can be tied to a different identity using configuration, allowing tokenized exchange to occur to provide authentication. In this configuration, Wildfire links a Kubernetes service account with a Google service account so that requests to Google APIs from our Kubernetes containers are automatically authenticated as the Google service account for both connectivity and user authentication. With these two steps we are able to completely remove database passwords from our infrastructure, relying on Google's authentication tools to handle both authentication and authorization to resources.
Role Based Access Control
Removing passwords from the infrastructure is great and a big step forward. But we can do better. In an ideal world, there is no need for developers to directly access infrastructure databases. In practice, however, there are bugs to research and manual processes to work through. By leveraging IAM authentication tied to individual users within our GCP project, we can provide clear audits of connections to the databases and quickly disable access in the event of a user breach or team member exit from the organization without disrupting any other users.
A Note On Postgres Roles
💡 A major lesson learned in this process was that under no circumstances should database objects be owned by an individual user. Wildfire defines several roles to which users are granted membership. At a minimum, we suggest a "reader" and "writer" role, with read-only and write access granted to these roles, respectively.
Additionally, we have granted ownership of database objects to the writer role to support our workloads. Further restrictions at the table or row level could be put in place with more fine-grained roles, as appropriate.
Privilege Escalation & Service Account Impersonation
Our individual users within the instance are all members of the most restrictive "reader" role. This allows them to authenticate and perform SELECT statements on our tables. However, they cannot directly write to the database using their own authentication. This allows our developers to login and perform investigative operations without concern of affecting a database directly, apart from potentially issuing a query that puts heavy load on the instance.
When an individual needs to make changes to the database, they can leverage service account impersonation to elevate their privileges temporarily to the level of a specific service account that is part of the writer group. This concept is similar to the Workload Identity performed at the Kubernetes level: a user is granted impersonation privileges on an account, then exchanges their own token for a token for the service account, which is then used for authentication to the database. Each step of this process is tracked within Google's audit logs, providing observability and traceability to the process. Once access has been obtained, the developer can perform their task and then drop the elevated privileges and resume read-only operations.
Even above write-access, we also created an administrative service account for use by our DevSecOps and management teams in the event of an urgent need. This service account belongs to the writer group and is also granted cloudsqlsuperuser permissions, allowing management of roles and other permissions. This eliminates the need for a Wildfire team member to ever login directly as a built-in user, providing clear audit logs of which actor performed a task.
Terraform
Theory is great, but at Wildfire, we are committed to going the extra mile to help others learn from our investment in security and reliability, so let's take a look at some Terraform to help you build this into your own stack. This will leverage Google Cloud as the provider, but similar solutions should be available at each of the major clouds.
IAM Roles
To begin, you'll need to create your service accounts and grant IAM access to these accounts and to each of your individual users. Within Google, this means allowing all your IAM users to create proxy connections and connect by binding the following roles:
- roles/cloudsql.client
- roles/cloudsql.instanceUser
locals {
managed_roles = {
"roles/cloudsql.client" : [
"group:team-acl@example.com",
"serviceAccount:cloudsql-administrator@google-project.iam.gserviceaccount.com",
"serviceAccount:cloudsql-writer@goolge-project.iam.gserviceaccount.com",
"user:jane.doe@example.com",
"user:john.doe@example.com"
],
"roles/cloudsql.instanceUser" : [
"group:team-acl@example.com",
"serviceAccount:cloudsql-administrator@google-project.iam.gserviceaccount.com",
"serviceAccount:cloudsql-writer@goolge-project.iam.gserviceaccount.com",
"user:jane.doe@example.com",
"user:john.doe@example.com"
],
}
project = "google-cloud-project"
}
resource "google_project_iam_binding" "binding" {
for_each = local.managed_roles
project = local.project
role = "projects/${local.project}/roles/${each.key}"
members = each.value
}
Now that we have permission to connect and authenticate to the database instance, we need to add these users to the instance itself as IAM users. The previous code block simply give permission at the project level, this section adds the specific users to the CloudSQL instance.
locals {
instance = "google-cloudsql-instance"
managed_users = [
{
name = "Jane Doe"
email = "jane.doe@example.com"
},
{
name = "John Doe"
email = "john.doe@example.com"
}
]
managed_service_accounts = [
{
name = "cloudsql-administrator"
email = "cloudsql-administrator@${local.project}.iam"
},
{
name = "cloudsql-writer"
email = "cloudsql-writer@${local.project}.iam"
}
]
project = "google-cloud-project"
}
resource "google_sql_user" "iam_users" {
for_each = {
for user in local.managed_users : user.name => user
}
name = each.value["email"]
instance = local.instance
project = local.project
type = "CLOUD_IAM_USER"
}
resource "google_sql_user" "iam_service_accounts" {
for_each = {
for sa in local.managed_service_accounts : sa.name => sa
}
name = each.value["email"]
instance = local.instance
project = local.project
type = "CLOUD_IAM_SERVICE_ACCOUNT"
}
💡 Note that prior to Postgres 15, a read-only user on the public schema can still create new tables. This must be avoided by training and review until you can migrate to a newer version of Postgres.
The last piece of configuration for access control is to allow the appropriate users to impersonate the writer or administrative service accounts. This is done by giving a list of users permission to create a service account token:
locals {
project = "google-cloud-project"
sa_assignments = {
"projects/${local.project}/serviceAccounts/cloudsql-administrator@${local.project}.iam.gserviceaccount.com" : {
role = "roles/iam.serviceAccountTokenCreator"
members = [
"group:team-acl@example.com",
"user:john.doe@example.com",
]
},
"projects/${local.project}/serviceAccounts/cloudsql-writer@${local.project}.iam.gserviceaccount.com" : {
role = "roles/iam.serviceAccountTokenCreator"
members = [
"group:team-acl@example.com",
"user:jane.doe@example.com",
"user:john.doe@example.com",
]
}
}
}
resource "google_service_account_iam_binding" "binding" {
for_each = {
for key, binding in local.sa_assignments : key => binding
}
role = each.value.role
members = each.value.members
service_account_id = each.key
}
Finally, we need to tie our Kubernetes service accounts to a Google service account. In this example, we’ll tie a service account called gcp-linked in Kubernetes to the cloudsql-writer@<project>.iam.
locals {
annotations = {
"iam.gke.io/gcp-service-account" = "${local.gcp_sa_name}"
}
gcp_sa_name = "cloudsql-writer@${local.project}.iam.gserviceaccount.com"
k8s_sa_name = "gcp-linked"
labels = {
"app.kubernetes.io/name" = "cloudsql-proxy"
}
project = "google-cloud-project"
}
resource "google_service_account_iam_binding" "k8s-sa-link" {
service_account_id = "projects/${local.project}/serviceAccounts/${local.gcp_sa_name}"
role = "roles/iam.workloadIdentityUser"
members = [
"serviceAccount:${local.project}.svc.id.goog[default/${local.k8s_sa_name}]",
]
}
resource "kubernetes_service_account" "account" {
metadata {
annotations = local.annotations
name = local.k8s_sa_name
namespace = "default"
labels = local.labels
}
automount_service_account_token = false
}
This configuration creates a Kubernetes service account with the proper annotations to bind it to our GCP service account and then also annotates the GCP service account to link it the other direction. With this in place, we can now use Workload Identity to issue requests within Kubernetes as if we were directly using the GCP service account.
Database Roles
Now that access control has been managed, we can turn to roles within the database. As previously mentioned, Wildfire leverages two roles, reader and writer to manage permissions within the database. All standard IAM users (individuals) are granted reader only, our cloudsql-writer service account is granted writer and our cloudsql-administrator account is granted writer and cloudsqlsuperuser to allow management of roles, objects and other administration. The built-in postgres users are only ever used for emergency recovery by our DevSecOps teams. Below you can see our basic Terraform to configure postgres. This leverages the excellent community module cyrilgdn/postgresql to manage the internals of a postgres instance regardless of where it is running.
💡 One thing to note here is that the postgresql provider does not support multiple database instances with the same provider config (authentication for the database, including the host, is built into the provider setup). If your team is managing multiple instances per environment, you will have to build multiple provider configurations with aliases to communicate with each database.
Additionally, this provider does not yet support IAM authentication itself, so Terraform still needs to leverage a built-in user to manage the grants and privileges.
terraform {
required_providers {
postgresql = {
source = "cyrilgdn/postgresql"
version = ">=1.19"
}
}
}
locals {
all_privileges_database = ["CREATE", "CONNECT", "TEMPORARY", "TEMP"]
all_privileges_sequence = ["SELECT", "UPDATE", "USAGE"]
all_privileges_table = ["SELECT", "INSERT", "UPDATE", "DELETE", "TRUNCATE", "REFERENCES", "TRIGGER"]
database = "my_db",
project = "google-cloud-project"
admins = [
"cloudsql-administrator@${local.project}.iam"
]
readers = [
"jane.doe@example.com",
"john.doe@example.com",
"cloudsql-administrator@${local.project}.iam",
"cloudsql-writer@${local.project}.iam"
],
writers = [
"cloudsql-administrator@${local.project}.iam",
"cloudsql-writer@${local.project}.iam"
]
}
# Create a no-login reader group role
# This will be used by all devs by default
resource "postgresql_role" "reader" {
name = "reader"
login = false
}
# Create a no-login writer group role
# This will be used for migrations and assumed
# when making changes to database tables
resource "postgresql_role" "writer" {
name = "writer"
login = false
# The writer role also needs to be granted
# the reader role so it can read objects.
roles = [postgresql_role.reader.name]
depends_on = [postgresql_role.reader]
}
# Grant all the readers the reader role
resource "postgresql_grant_role" "reader" {
for_each = toset(local.readers)
grant_role = "reader"
role = each.value
depends_on = [postgresql_role.reader]
}
# Grant all the writers the writer role
resource "postgresql_grant_role" "writer" {
for_each = toset(local.writers)
grant_role = "writer"
role = each.value
depends_on = [postgresql_role.reader, postgresql_role.writer]
}
# Grant all the admins the cloudsqlsuperuser role
resource "postgresql_grant_role" "cloudsqlsuperuser-admin" {
for_each = toset(local.admins)
grant_role = "cloudsqlsuperuser"
role = each.value
with_admin_option = true
depends_on = [postgresql_role.reader, postgresql_role.writer]
}
# Grant all the admins the reader role with role administration
resource "postgresql_grant_role" "reader-admin" {
for_each = toset(local.admins)
grant_role = "reader"
role = each.value
with_admin_option = true
depends_on = [postgresql_role.reader]
}
# Grant all the admins the writer role with role administration
resource "postgresql_grant_role" "writer-admin" {
for_each = toset(local.admins)
grant_role = "writer"
role = each.value
with_admin_option = true
depends_on = [postgresql_role.reader, postgresql_role.writer]
}
resource "postgresql_default_privileges" "read_only_tables" {
role = "reader"
database = local.database
schema = "public"
owner = "writer"
object_type = "table"
privileges = ["SELECT"]
}
resource "postgresql_default_privileges" "read_only_sequences" {
role = "reader"
database = local.database
schema = "public"
owner = "writer"
object_type = "sequence"
privileges = ["SELECT"]
}
resource "postgresql_default_privileges" "all_tables" {
role = "writer"
database = local.database
schema = "public"
owner = "writer"
object_type = "table"
privileges = local.all_privileges_table
}
resource "postgresql_default_privileges" "all_sequences" {
role = "writer"
database = local.database
schema = "public"
owner = "writer"
object_type = "sequence"
privileges = local.all_privileges_sequence
}
Object Ownership
Earlier, we called out object ownership as a key part of this process. Now that your database has a large number of unique users, you must avoid object ownership by any one user, instead granting ownership to a group. To do this, we have integrated a CI flow that requires all our database migrations (table creation and manipulation) to begin with a line that sets the current role for the migration to the writer group. Without this, objects would be owned by the current user, causing potential issues in the future if that user is unavailable or has left the organization:
SET ROLE writer;
If you are transitioning to IAM on an already-active database, you will also have to transition ownership of all existing objects to the group. At Wildfire, this included types, tables, sequences, views, schemas, functions and materialized views. Depending on your team’s use cases, you may have greater or fewer things to migrate.
Connecting
At Wildfire, we have three main ways of connecting to the database:
- In our Go code on a local machine for testing or debugging
- Through a postgres docker container on a local machine
- In our infrastructure in a Kubernetes container
In this section, we’ll cover each of these use cases from a functional level to show you how to leverage IAM to support them.
Go Code
Go’s lib/pq package handles normal postgres connections and github.com/GoogleCloudPlatform/cloudsql-proxy/proxy/dialers/postgres handles connections to CloudSQL instances by automatically configuring the proxy connection without running a sidecar container. However, neither of these drivers support IAM authentication to Google, so we needed to pull in the cloud.google.com/go/cloudsqlconn/postgres/pgxv4 driver to support our desired workflow. This requires registering an additional driver as shown below. This is actual code from our postgres management package:
func init() {
conf := config.NewConfig()
// Register a new driver for using IAM authentication to the database instead of a password.
// This driver also supports password authentication, but we are moving away from that and
// cannot override the default `cloudsqlpostgres` that we get built-in.
if conf.GetBool("service_account_impersonation") {
// If we are impersonating a service account, we need to add the impersonation email to both token sources.
// Base credentials sourced from ADC.
var ctx = context.Background()
sa_email := conf.GetString("service_account_impersonation_email")
// This token source is used for Cloud SQL administrative APIs, basically setting up the proxy connection.
apiTs, err := impersonate.CredentialsTokenSource(ctx, impersonate.CredentialsConfig{
TargetPrincipal: sa_email,
Scopes: []string{"https://www.googleapis.com/auth/cloud-platform", "https://www.googleapis.com/auth/sqlservice.admin"},
})
if err != nil {
panic(err)
}
// This token source is scoped much narrower, only allowing login to the actual SQL instance. You could
// technically use the same token source for both, but this is more secure.
loginTs, err := impersonate.CredentialsTokenSource(ctx, impersonate.CredentialsConfig{
TargetPrincipal: sa_email,
Scopes: []string{"https://www.googleapis.com/auth/sqlservice.login"},
})
if err != nil {
panic(err)
}
if _, err := pgxv4.RegisterDriver("cloudsql_postgres", cloudsqlconn.WithIAMAuthN(), cloudsqlconn.WithIAMAuthNTokenSources(apiTs, loginTs)); err != nil {
// Something awful happened, it's going to explode anyway, so just panic.
panic(err)
}
} else {
// If we're not impersonating a service account, we can just use the default ADC token source.
if _, err := pgxv4.RegisterDriver("cloudsql_postgres", cloudsqlconn.WithIAMAuthN()); err != nil {
// Something awful happened, it's going to explode anyway, so just panic.
panic(err)
}
}
}
In order to leverage this, you need to have your application default credentials (ADC) configured correctly and request the cloudsql_postgres driver, then provide the right URI arguments to the driver. An example can be seen here, notice that none of these values is secret any longer, so they can be checked in alongside the code for ease of discovery for other developers:
export GOOGLE_IAM_EMAIL=`gcloud config get-value core/account`
DB_DRIVER=cloudsql_postgres DB_URI="host=<project>:<location>:<instance_name> dbname=my_db user=$GOOGLE_IAM_EMAIL" go run .
To use service account impersonation locally while running your go code, you can add a couple more flags:
GOOGLE_IAM_EMAIL=cloudsql-writer@<project>.iam SERVICE_ACCOUNT_IMPERSONATION=true SERVICE_ACCOUNT_IMPERSONATION_EMAIL=cloudsql-writer@<project>.iam.gserviceaccount.com DB_DRIVER=cloudsql_postgres DB_URI="host=<project>:<location>:<instance_name> user=$GOOGLE_IAM_EMAIL dbname=my_db" go run .
Docker Containers
For a number of reasons, it can be advantageous to connect directly to a psql command line interface at times. Now that we have the ability to restrict standard users to read-only, this is a much less scary proposition. At Wildfire, we run a cloudsql-<environment> container to handle the proxying of our connections to CloudSQL (-i is the flag to support IAM authentication at the proxy level):
cloudsql-dev='docker run -d --name cloudsql-dev -v $HOME.config/gcloud/application_default_credentials.json:/config gcr.io/cloud-sql-connectors/cloud-sql-proxy:2.7.0 -i -c /config --port 5433 --address 0.0.0.0 <project>:<location>:<instance_name>'
We also provide an alias for connecting as the various service accounts for writing and administration, requiring users to start the correct proxy for the actions they wish to take and ensuring fewer users are "always" escalating:
alias cloudsql-dev-writer='docker run -d --name cloudsql-dev -v $HOME.config/gcloud/application_default_credentials.json:/config gcr.io/cloud-sql-connectors/cloud-sql-proxy:2.2.0 -i --impersonate-service-account=cloudsql-writer@<project>.iam.gserviceaccount.com -c /config --port 5433 --address 0.0.0.0 <project>:<location>:<instance_name>'
alias cloudsql-dev-admin='docker run -d --name cloudsql-dev -v $HOME.config/gcloud/application_default_credentials.json:/config gcr.io/cloud-sql-connectors/cloud-sql-proxy:2.2.0 -i --impersonate-service-account=cloudsql-administrator@<project.iam.gserviceaccount.com -c /config --port 5433 --address 0.0.0.0 <project>:<location>:<instance_name>'
With the proxies up and running, you can start a second container and link to it to provide clean access to the database with only IAM authentication:
alias psql-dev='docker run -v $HOME/.pg_service.conf:/.pg_service.conf -e GOOGLE_IAM_EMAIL=$GOOGLE_IAM_EMAIL -e PGSERVICEFILE=/.pg_service.conf --rm -it --link cloudsql-dev postgres:15.4-alpine psql -U $GOOGLE_IAM_EMAIL --set=db=my_db service=postgres-dev-my_db'
Kubernetes
Now that IAM and Workload Identity are configured, this is actually the simplest setup. By configuring your Kubernetes job to use the proper service account, you get all the other authentication pieces for free and you can just provide the right DB_URI in the environment. In the deployment, this can then be a plaintext environment variable:
env:
- name: DB_URI
value: host=<project>:<location>:<instance_name> dbname=my_db user=<google-service-account>
...
serviceAccount: gcp-linked
Any Kubernetes job not using this gcp-linked service account will now be unable to authenticate to the database, while all properly annotated jobs will have full authentication handled automatically without any secrets injected into the cluster.
Conclusion
This can seem like a considerable amount of complexity and configuration just for database access. However, the benefits far outweigh the effort. The removal of built-in users from daily operations provides significant security and observability improvements. Password rotations are no longer required when an employee leaves or is reassigned. Service account keys can be removed entirely from infrastructure and user machines. Users default to read-only access and escalations to write-enabled accounts are tracked, showing which user escalated and when.
As we continue to push to a zero-trust environment, this marks a significant improvement to our security posture. We hope this blog post helps you get started down your own path of improvement and stronger security. If working on these types of projects is interesting to you, keep an eye on our Indeed page for open developer roles.


